The Tech Behind DeepPack (Part 4)
October 28, 2022

October 28, 2022
DeepPack Infrastructure
DeepPack components
The high-performance computing infrastructure behind DeepPack is an integral part of the product: it is running constantly in the background to quickly deliver accurate optimization results of very complex instances.
As previously mentioned in part 3 of the blog, the user can select between two types of runs: instant and optimized. An in instant run provides a fast result in a matter of seconds. The optimized run delivers better results as the algorithm would work harder to further enhance the load plan. This type of run typically requires compute resources and is performed on a cluster of supercomputers, leveraging High-Performance Computing techniques and a combination of GPUs/CPUs.
InstaDeep has long-term experience in managing compute assets at scale including Nvidia GPUs and Google TPUs. InstaDeep is indeed an Elite Partner of Nvidia and operates its own cluster and is also a Google Cloud Service and Build Partner. For industrial usage of DeepPack and for large operators looking for maximum efficiency, it is a worthwhile investment to leverage compute resources and monitor usage and consumption.
High-level overview of the infrastructure
Different components
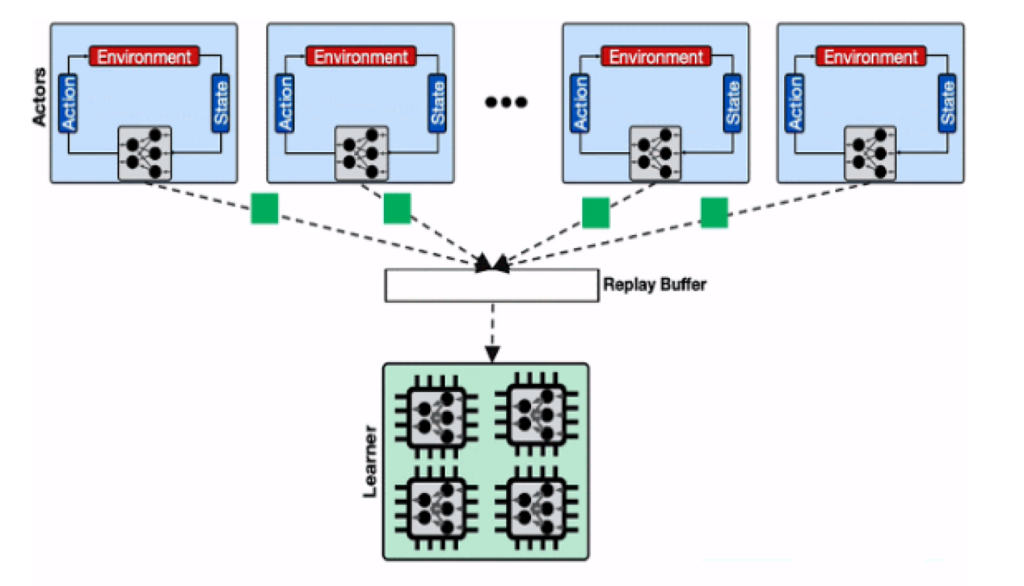
To run any algorithm of choice at scale, we developed our own platform which facilitates the distribution of the workload on our own infrastructure.
It uses the common Actor-Learner architecture, where the learner consumes data in large batches and performs gradient descent updates on the Nvidia A100 DGX machine, while the actors are distributed to hundreds of CPUs to keep up with the learner consumption.
Actors and learners both run asynchronously in parallel and the updated parameters are sent to the actors on periodic bases to stay as close to on-policy as possible. Besides efficient scaling, other advantages of our framework are as follows:
- Algorithms can be easily distributed by design.
- Standardized and structured communication with our computation infrastructure.
- Agnostic to the DL frameworks.
- Relies on Ray for Distributing Computation.
Shoutout to Nvidia and Google partnership
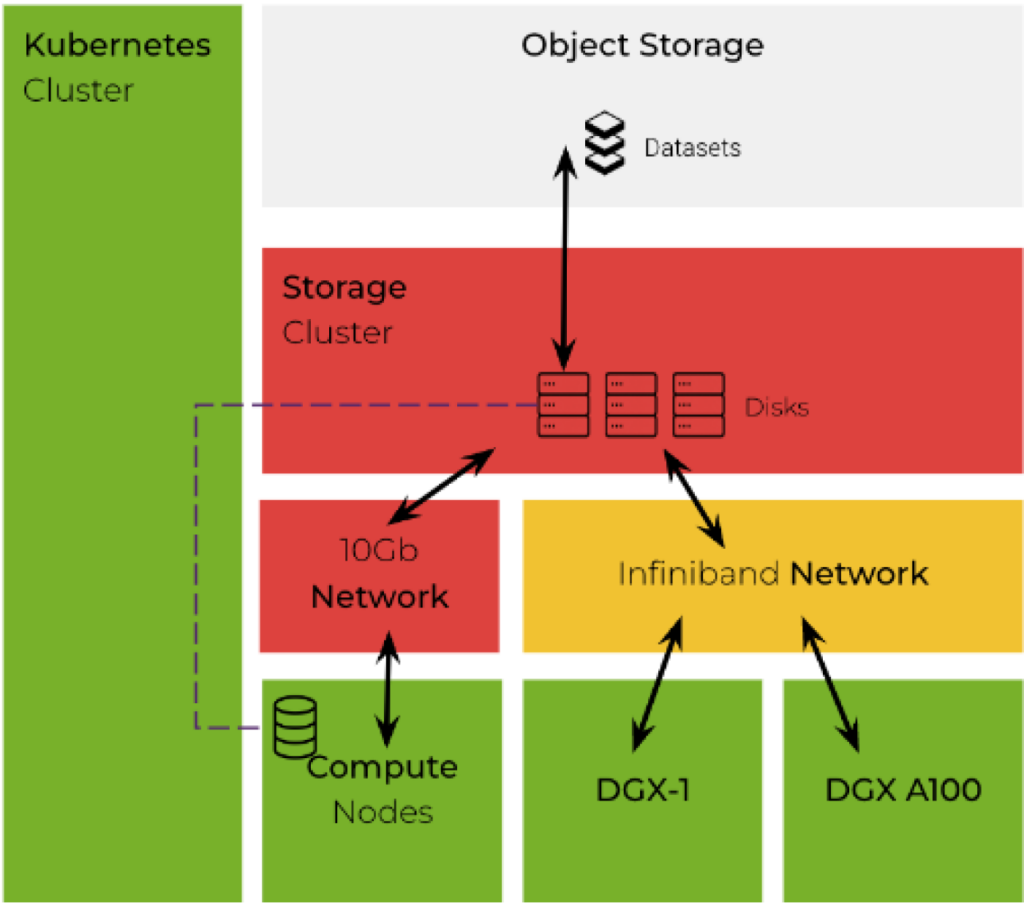
DeepPack is built on expert ML infrastructure offered by Nvidia of which we are an Elite Partner. DeepPack is hosted on the enterprise-grade orchestration platform Kubernetes, which incorporates some of the powerful machines that accelerate our workloads efficiently, notably the Nvidia A100 DGX.
With the help of GPU partitioning offered by Nvidia Multi-Instance GPU (MIG) technology, we are able to support every workload, from the smallest to the largest, with guaranteed Quality of Service (QoS) and extend the usability of powerful machines to every use case.
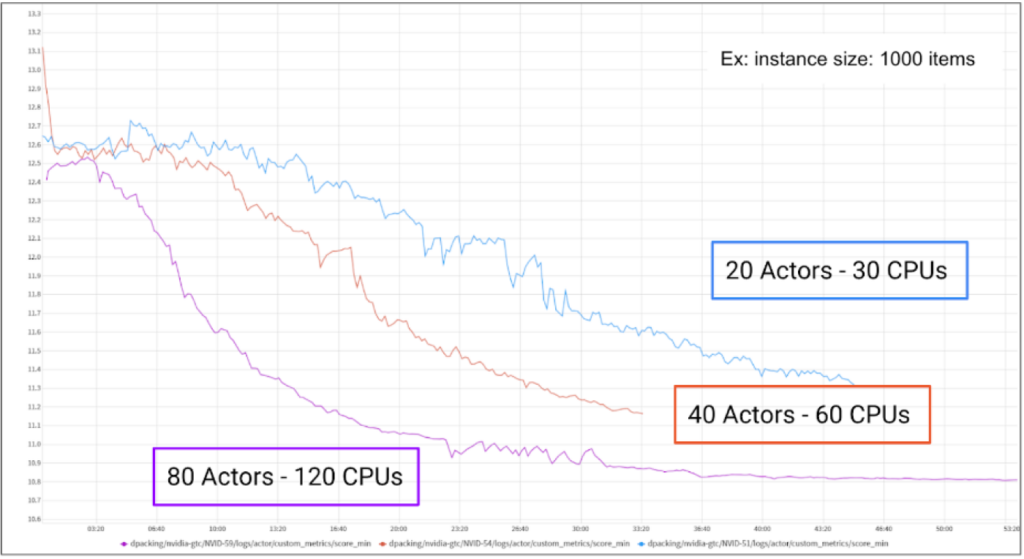
Unlocking scalability
With our state-of-the-art algorithms & computing infrastructure, we can accommodate high usage requirements, and quickly solve complex load plans. DeepPack is scalable for large instances. In fact, we have a 3X Faster Convergence for 3D Bin Packing Large Instances.
DeepPack’s infrastructure allows us to scale and expand the product’s scope by incorporating new features and constraints depending on our client’s operational and technical requirements.
If you would like to test DeepPack on your own data, we have extended our Early Access Program until the end of the year, free of charge. Additionally, participants will benefit from an exclusive discounted pricing tier.
If you have any questions, get in touch at hello@deeppack.ai







Share this article